SPARK Using Python and Scala
Other resources:
https://jaceklaskowski.gitbooks.io/mastering-apache-spark/content/
Ecosystem
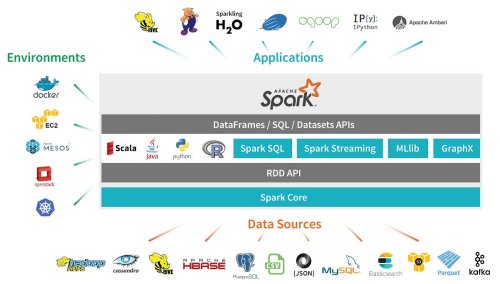
source: https://analyticks.wordpress.com/2016/09/19/7-steps-to-mastering-apache-spark-2-0/
| Part | Description |
|---|---|
| RDD | It is an immutable (read-only) distributed collection of objects. Each dataset in RDD is divided into logical partitions, which may be computed on different nodes of the cluster. RDDs can contain any type of Python, Java, or Scala objects, including user-defined classes. |
| Spark Core | Spark Core is the foundation of the overall project. It provides distributed task dispatching, scheduling, and basic I/O functionalities, exposed through an application programming interface. |
| Spark SQL | Spark SQL is a component on top of Spark Core that introduced a data abstraction called DataFrames |
| Spark Streaming | Spark Streaming uses Spark Core's fast scheduling capability to perform streaming analytics |
| MLlib Machine Learning Library | Spark MLlib is a distributed machine learning framework on top of Spark Core that, due in large part to the distributed memory-based Spark architecture |
| GraphX | GraphX is a distributed graph processing framework on top of Apache Spark |
https://en.wikipedia.org/wiki/Apache_Spark
All data and sources can be found in free eDX course
https://courses.edx.org/courses/course-v1:Microsoft+DAT202.3x+2T2018/course/
DataFrame
Schema Create
from pyspark.sql.types import *
flightSchema = StructType([
StructField("DayofMonth", IntegerType(), False),
StructField("DayOfWeek", IntegerType(), False),
StructField("Carrier", StringType(), False),
StructField("OriginAirportID", IntegerType(), False),
StructField("DestAirportID", IntegerType(), False),
StructField("DepDelay", IntegerType(), False),
StructField("ArrDelay", IntegerType(), False),
])
import org.apache.spark.sql.Encoders
case class flight(
DayofMonth:Int,
DayOfWeek:Int,
Carrier:String,
OriginAirportID:Int,
DestAirportID:Int,
DepDelay:Int,
ArrDelay:Int)
val flightSchema = Encoders.product[flight].schema
createDataFrame()
# 
from pyspark.sql.types import *
from pyspark.sql.functions import *
data = spark.createDataFrame([
("A", 1),
("B", 2),
("C", 3),
("Very long text to show", 4)],["text", "value"])
data.show()
import org.apache.spark.sql.types._
import org.apache.spark.sql.functions._
val data = spark.createDataFrame(Seq(
("A", 1),
("B", 2),
("C", 3),
("Very long text to show", 4))).toDF("text", "value")
data.show()
read.csv()
flights = spark.read.csv(
'wasb:///data/raw-flight-data.csv',
schema=flightSchema,
header=True)
val flights = spark.read.schema(flightSchema).
option("header", "true").
csv("wasb:///data/raw-flight-data.csv")
Without schema
airports = spark.read.csv('wasb:///data/airports.csv',
header=True,
inferSchema=True)
airports = spark.read.csv('wasb:///data/airports.csv',
header=True,
inferSchema=True)
.printSchema()
# 
airports.printSchema()
airports.printSchema()
.show()
# 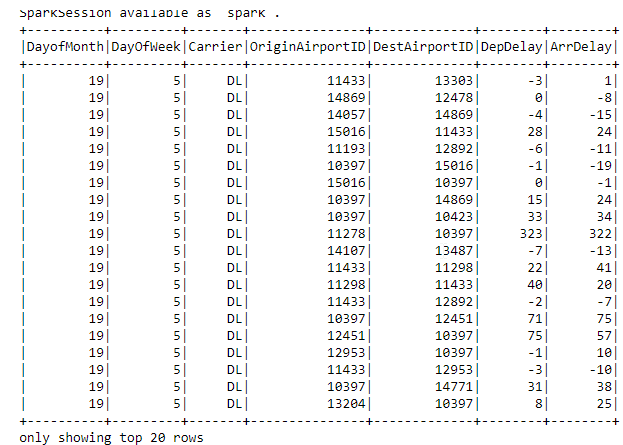
flights.show()
flights.show()
Show 30 rows
# 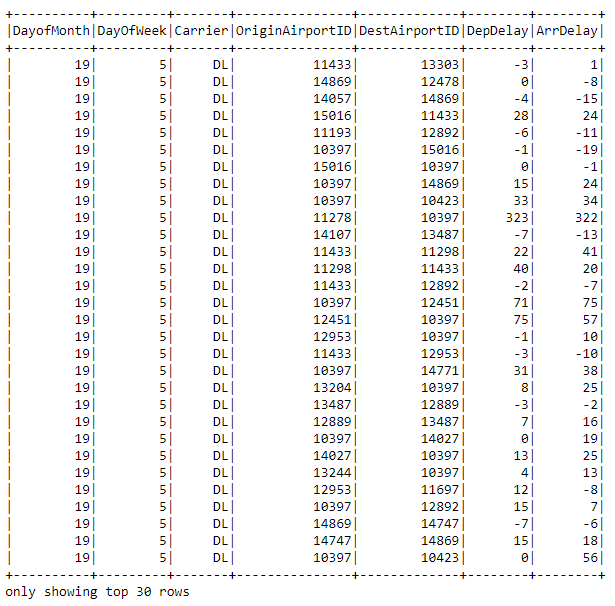
flights.show(30)
flights.show(30)
Show all text
# 
data.show(5,truncate = False)
data.show(5,truncate = false)
.count()
# res6: Long = 2719418
flights.count()
flights.count()
.describe()
Show statistics about DataFrame
# 
flights.describe().show()
flights.describe().show()
Select
.select()
# 
cities = airports.select("city", "name")
cities.show()
val cities = airports.select("city", "name")
cities.show()
.select() / columns
| function | description |
|---|---|
| col | return column by name |
| cast | cast to type |
| alias | set name of column |
# 
from pyspark.sql.types import *
from pyspark.sql.functions import *
flights.select( "ArrDelay", (
(col("ArrDelay") > 15).cast("Int").alias("label")
))
import org.apache.spark.sql.types._
import org.apache.spark.sql.functions._
flights.select( $"ArrDelay",
($"ArrDelay" > 15).cast("Int").alias("Late")
)
.filter()
# 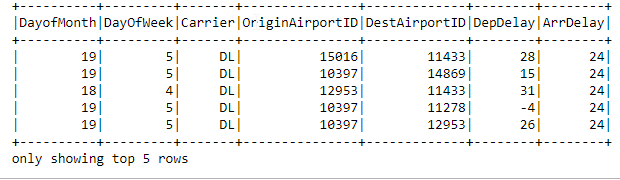
flights.filter("ArrDelay==24")
flights.filter("ArrDelay==24")
.dropDuplicates()
flights.dropDuplicates()
flights.dropDuplicates()
.drop N/A
| parameter | description |
|---|---|
| how | ‘any’ or ‘all’. If ‘any’, drop a row if it contains any nulls. If ‘all’, drop a row only if all its values are null. |
| subset | list of column names to drop |
flights.dropna(how="any", subset=["ArrDelay", "DepDelay"])
flights.na.drop("any", Array("ArrDelay", "DepDelay"))
.fill N/A
flights.fillna(0, subset=["ArrDelay", "DepDelay"])
flights.na.fill(0, Array("ArrDelay", "DepDelay"))
.join() / .groupBy()
# 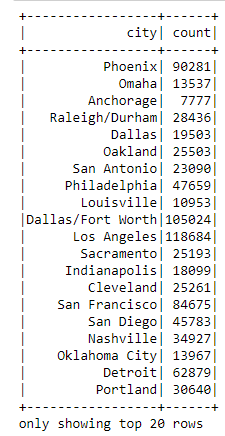
flightsByOrigin = flights.join(airports,
flights.OriginAirportID == airports.airport_id
).groupBy("city").count()
flightsByOrigin.show()
val flightsByOrigin = flights.join(airports,
$"OriginAirportID" === $"airport_id"
).groupBy("city").count()
flightsByOrigin.show()
.corr()
Dsiplay correlation between two columns
# Double = 0.9392036350446951
flights.corr("DepDelay","ArrDelay")
flights.stat.corr("DepDelay","ArrDelay")
.withColumnRenamed()
Rename column
# 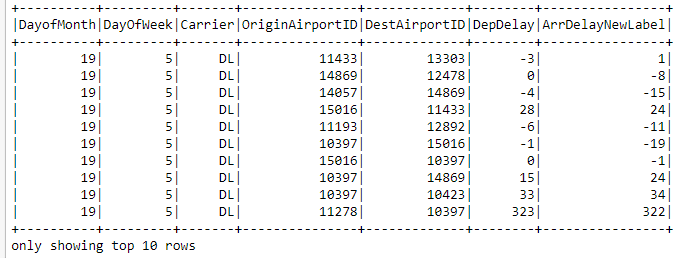
data = flights.withColumnRenamed("ArrDelay", "ArrDelayNewLabel")
val data = flights.withColumnRenamed("ArrDelay", "ArrDelayNewLabel")
sql()/.createOrReplaceTempView()
Create Temporary table that can be selected by the sql from the name of DataFrame
# 
flights.createOrReplaceTempView("flightData")
spark.sql("SELECT DayOfWeek, AVG(ArrDelay) AS AvgDelay \
FROM flightData \
GROUP BY DayOfWeek ORDER BY DayOfWeek").show()
flights.createOrReplaceTempView("flightData")
spark.sql("SELECT DayOfWeek, AVG(ArrDelay) AS AvgDelay FROM flightData GROUP BY DayOfWeek ORDER BY DayOfWeek").show()
%%sql / from jupyter
# 
%%sql
SELECT DepDelay, ArrDelay FROM flightData
airports.createOrReplaceTempView("airportData")
# 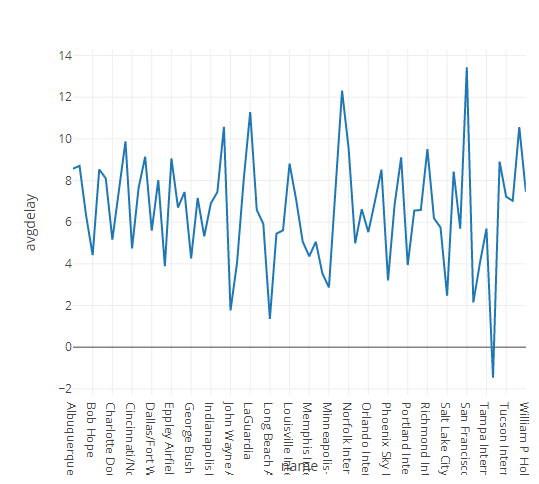
%%sql
SELECT a.name, AVG(f.ArrDelay) AS avgdelay
FROM flightData AS f JOIN airportData AS a
ON f.DestAirportID = a.airport_id
GROUP BY a.name
Split Data
.randomSplit()
Flights: 2719418 rows, Train: 1903414 rows, Test: 816004 rows
splits = flights.randomSplit([0.7, 0.3])
train = splits[0]
test = splits[1]
val splits = flights.randomSplit(Array(0.7, 0.3))
val train = splits(0)
val test = splits(1)
Pipeline
https://spark.apache.org/docs/latest/ml-pipeline.html
Instead of doing precalculations again we can create pipeline for all steps before calculate train, test data and also predict, fit model after or calculations after.
Preprocessing / Prepare Data
from pyspark.ml import Pipeline
from pyspark.ml.feature import VectorAssembler, StringIndexer, VectorIndexer, MinMaxScaler
import org.apache.spark.ml.Pipeline
import org.apache.spark.ml.feature.{VectorAssembler, StringIndexer, VectorIndexer, MinMaxScaler}
StringIndexer
Convert string to categories numbers
# 
from pyspark.ml.feature import StringIndexer
strIdx = StringIndexer(inputCol = "Carrier", outputCol = "CarrierIdx")
data2 = strIdx.fit(train).transform(train)
data2.select("Carrier","carrierIdx").show(5)
import org.apache.spark.ml.feature.StringIndexer
val strIdx = new StringIndexer().setInputCol("Carrier").setOutputCol("CarrierIdx")
val data2 = strIdx.fit(train).transform(train)
data2.select("Carrier","carrierIdx").show(5)
VectorAssembler
Create Vector with all features for training
# 
from pyspark.ml.feature import VectorAssembler
assembler = VectorAssembler(
inputCols = ["DayofMonth", "DayOfWeek","DestAirportID"],
outputCol="features")
training = assembler.transform(train)
training.select("DayofMonth",
"DayOfWeek",
"OriginAirportID",
"features").show(5)
val assembler = new VectorAssembler().setInputCols(
Array("DayofMonth", "DayOfWeek", "OriginAirportID")).
setOutputCol("features")
val training = assembler.transform(train)
training.select("DayofMonth",
"DayOfWeek",
"OriginAirportID",
"features").show(5)
VectorIndexer
Index categorical features as vector. (in Decision Tree or Tree Ensembles)
# 
from pyspark.ml.feature import VectorIndexer
catVect = VectorAssembler(inputCols =
["CarrierIdx",
"DayofMonth", "DayOfWeek",
"OriginAirportID", "DestAirportID"],
outputCol="catFeatures")
data3 = catVect.transform(data2)
catIdx = VectorIndexer(
inputCol = catVect.getOutputCol(),
outputCol = "idxCatFeatures") # catFeatures
data4 = catIdx.fit(data3).transform(data3)
data4.select("catFeatures","idxCatFeatures").show(5)
import org.apache.spark.ml.feature.VectorIndexer
val catVect = new VectorAssembler().setInputCols(Array("CarrierIdx", "DayofMonth", "DayOfWeek", "OriginAirportID", "DestAirportID")).setOutputCol("catFeatures")
val data3 = catVect.transform(data2)
val catIdx = new VectorIndexer().
setInputCol(catVect.getOutputCol).
setOutputCol("idxCatFeatures")
val data4 = catIdx.fit(data3).transform(data3)
data4.select("catFeatures","idxCatFeatures").show(5)
MinMaxScaler
Scaling features
# 
from pyspark.ml.feature import MinMaxScaler
numVect = VectorAssembler(inputCols = ["DepDelay"],
outputCol="numFeatures")
data5 = numVect.transform(data4)
minMax = MinMaxScaler(inputCol = numVect.getOutputCol(),
outputCol="normFeatures")
data6 = minMax.fit(data5).transform(data5)
data6.select("numFeatures","normFeatures").show(5)
import org.apache.spark.ml.feature.MinMaxScaler
val numVect = new VectorAssembler().
setInputCols(Array("DepDelay")).
setOutputCol("numFeatures")
val data5 = numVect.transform(data4)
val minMax = new MinMaxScaler().
setInputCol(numVect.getOutputCol).
setOutputCol("normFeatures")
val data6 = minMax.fit(data5).transform(data5)
data6.select("numFeatures","normFeatures").show(5)
Pipeline
Instead of transform and move each step we define a Pieline for all of them with stages.
# 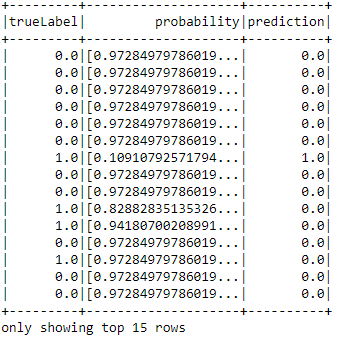
from pyspark.ml import Pipeline
from pyspark.ml.classification import DecisionTreeClassifier
featVect = VectorAssembler(
inputCols=["idxCatFeatures", "normFeatures"],
outputCol="features")
dt = DecisionTreeClassifier(
labelCol="label",
featuresCol="features")
pipeline = Pipeline(stages=[
strIdx, catVect, catIdx,
numVect, minMax, featVect, dt])
model = pipeline.fit(train)
model.transform(test).select(
"trueLabel", "probability","prediction").show(15)
import org.apache.spark.ml.Pipeline
import org.apache.spark.ml.classification.DecisionTreeClassifier
val featVect = new VectorAssembler().
setInputCols(Array("idxCatFeatures", "normFeatures")).
setOutputCol("features")
val dt = new DecisionTreeClassifier().
setLabelCol("label").
setFeaturesCol("features")
val pipeline = new Pipeline().
setStages(Array(strIdx, catVect, catIdx,
numVect, minMax, featVect, dt))
val model = pipeline.fit(train)
model.transform(test).select(
"trueLabel", "probability","prediction").show(15)
Classification
LogisticRegression()
Preprocessing / Prepare Data
| LogisticRegression parameters | Description |
|---|---|
| labelCol | column with true values |
| featuresCol | column with featurs made by assembler |
| maxIter | maximum number of iteration |
| regParam | regularization parameter |
| threshold | set treshold (<0.5 - more true values, >0.5 more false values) |
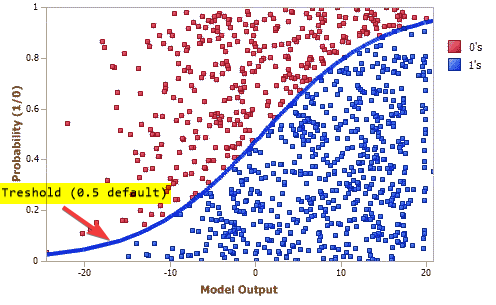
Train / fit()
from pyspark.ml.classification import LogisticRegression
from pyspark.ml import Pipeline
lr = LogisticRegression(
labelCol="label",
featuresCol="features",
maxIter=10,
regParam=0.3,
threshold=0.35)
pipeline = Pipeline(stages=[assembler, lr])
model = pipeline.fit(train)
import org.apache.spark.ml.Pipeline
import org.apache.spark.ml.classification.LogisticRegression
val lr = new LogisticRegression().
setLabelCol("label").
setFeaturesCol("features").
setMaxIter(10).
setRegParam(0.3).
setThreshold(0.35)
val pipeline = new Pipeline().setStages(Array(assembler, lr))
// Train the model
val model = pipeline.fit(train)
Test / predict()
# 
predicted = model.transform(test).\
select("features","label", "probability", "prediction")
val predicted = model.transform(test).
select("features", "label","probability", "prediction")
Evaluator / BinaryClassificationEvaluator
| parameter | description |
|---|---|
| labelCol | Column with True value |
| rawPredictionCol | Predicted column |
| metricName | metric (areaUnderROC, areaUnderPR) |
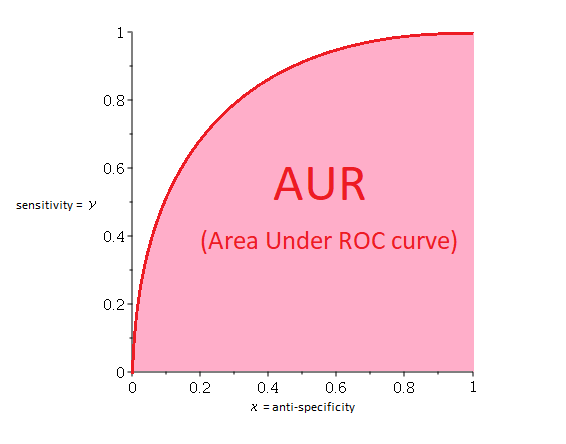
0.560080941553643
from pyspark.ml.evaluation import BinaryClassificationEvaluator
evaluator = BinaryClassificationEvaluator(
labelCol="label",
rawPredictionCol="prediction",
metricName="areaUnderROC")
evaluator.evaluate(predicted)
import org.apache.spark.ml.evaluation.BinaryClassificationEvaluator
val evaluator = new BinaryClassificationEvaluator().
setLabelCol("label").
setRawPredictionCol("prediction").
setMetricName("areaUnderROC")
val auc = evaluator.evaluate(predicted)
println(auc)
Evaluator / MulticlassClassificationEvaluator
| parameter | description |
|---|---|
| labelCol | Column with True value |
| rawPredictionCol | Predicted column |
| metricName | metric (f1,accuracy, weightedPrecision,weightedRecall) |
0.8248030889173621
from pyspark.ml.evaluation import MulticlassClassificationEvaluator
evaluator = MulticlassClassificationEvaluator(
labelCol="label",
predictionCol="prediction",
metricName="accuracy")
evaluator.evaluate(predicted)
import org.apache.spark.ml.evaluation.MulticlassClassificationEvaluator
val evaluator = new MulticlassClassificationEvaluator().
setLabelCol("label").
setPredictionCol("prediction").
setMetricName("accuracy")
val auc = evaluator.evaluate(predicted)
println(auc)
Evaluator / Confusion Matrix

tp = float(predicted.filter("prediction == 1.0 AND label == 1").count())
fp = float(predicted.filter("prediction == 1.0 AND label == 0").count())
tn = float(predicted.filter("prediction == 0.0 AND label == 0").count())
fn = float(predicted.filter("prediction == 0.0 AND label == 1").count())
metrics = spark.createDataFrame([
("TP", tp),
("FP", fp),
("TN", tn),
("FN", fn),
("Precision", tp / (tp + fp)),
("Recall", tp / (tp + fn))],["metric", "value"])
metrics.show()
val tp = predicted.filter("prediction == 1 AND label == 1").count().toFloat
val fp = predicted.filter("prediction == 1 AND label == 0").count().toFloat
val tn = predicted.filter("prediction == 0 AND label == 0").count().toFloat
val fn = predicted.filter("prediction == 0 AND label == 1").count().toFloat
val metrics = spark.createDataFrame(Seq(
("TP", tp),
("FP", fp),
("TN", tn),
("FN", fn),
("Precision", tp / (tp + fp)),
("Recall", tp / (tp + fn)))).toDF("metric", "value")
metrics.show()
Regression Model
Preprocessing / Prepare Data
LinearRegression()
| LogisticRegression parameters | Description |
|---|---|
| labelCol | column with true values |
| featuresCol | column with featurs made by assembler |
| maxIter | maximum number of iteration |
| regParam | regularization parameter |
from pyspark.ml.regression import LinearRegression
lr = LinearRegression(
labelCol="label",
featuresCol="features",
maxIter=10,
regParam=0.3)
import org.apache.spark.ml.regression.LinearRegression
val lr = new LinearRegression().
setLabelCol("label").
setFeaturesCol("features").
setMaxIter(10).
setRegParam(0.3)
Train / fit()
pipeline = Pipeline(stages=[assembler, lr])
piplineModel = pipeline.fit(train)
val pipeline = new Pipeline().setStages(Array(assembler, lr))
// Train the model
val model = pipeline.fit(train)
Test / predict()
# 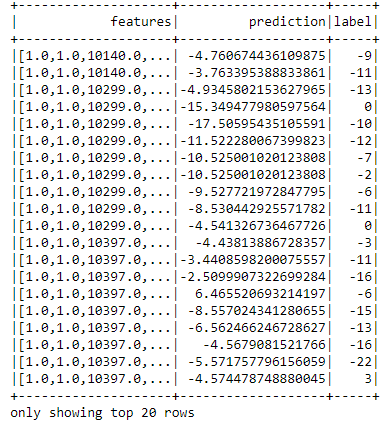
prediction = piplineModel.transform(test)
prediction.select("features", "prediction", "label").show()
val prediction = model.transform(test)
prediction.select("features", "prediction", "label").show()
Evaluate / RegressionEvaluator
| parameter | description |
|---|---|
| labelCol | Column with True value |
| rawPredictionCol | Predicted column |
| metricName | metric |
rmse - Root mean squared error | |
mse - Mean squared error | |
r2 - Regression through the origin (higher is better) | |
mae - Mean absolute error |
('Root Mean Square Error (RMSE):', 13.20959903047194)
from pyspark.ml.evaluation import RegressionEvaluator
evaluator = RegressionEvaluator(
labelCol="label",
predictionCol="prediction",
metricName="rmse")
rmse = evaluator.evaluate(prediction)
print("Root Mean Square Error (RMSE):", rmse)
import org.apache.spark.ml.evaluation.RegressionEvaluator
val evaluator = new RegressionEvaluator().
setLabelCol("label").
setPredictionCol("prediction").
setMetricName("rmse")
val rmse = evaluator.evaluate(prediction)
println("Root Mean Square Error (RMSE): " + (rmse))
Parameter tunning
TrainValidationSplit()
https://spark.apache.org/docs/latest/ml-tuning.html
Preprocessing / Prepare Data
ParamGridBuilder()
| function | description |
|---|---|
| .addGrid() | Adds a long param with multiple values. |
| .build() | Builds and returns all combinations of parameters specified by the param grid. |
TrainValidationSplit ()
| parameter | description |
|---|---|
| estimator | pipeline or model to estimate parameters |
| evaluator | evaluator to get best parameters |
| estimatorParamMaps | grid of parameters |
| trainRatio | Param for ratio between train and validation data. |
from pyspark.ml.tuning import ParamGridBuilder, TrainValidationSplit
paramGrid = ParamGridBuilder().\
addGrid(lr.regParam, [0.3, 0.1, 0.01]).\
addGrid(lr.maxIter, [10, 5]).\
addGrid(lr.threshold, [0.35, 0.30]).build()
tvs = TrainValidationSplit(
estimator=pipeline,
evaluator=BinaryClassificationEvaluator(),
estimatorParamMaps=paramGrid,
trainRatio=0.8)
model = tvs.fit(train)
import org.apache.spark.ml.tuning.{ParamGridBuilder, TrainValidationSplit}
val paramGrid = new ParamGridBuilder().
addGrid(lr.regParam, Array(0.3, 0.1, 0.01)).
addGrid(lr.maxIter, Array(10, 5)).
addGrid(lr.threshold, Array(0.35, 0.3)).
build()
val tvs = new TrainValidationSplit().
setEstimator(pipeline).
setEvaluator(new BinaryClassificationEvaluator).
setEstimatorParamMaps(paramGrid).
setTrainRatio(0.8)
val model = tvs.fit(train)
Evaluate

0.85505902838
prediction = model.transform(test)
tp = float(prediction.filter("prediction == 1.0 AND truelabel == 1").count())
fp = float(prediction.filter("prediction == 1.0 AND truelabel == 0").count())
tn = float(prediction.filter("prediction == 0.0 AND truelabel == 0").count())
fn = float(prediction.filter("prediction == 0.0 AND truelabel == 1").count())
metrics = spark.createDataFrame([
("TP", tp),
("FP", fp),
("TN", tn),
("FN", fn),
("Precision", tp / (tp + fp)),
("Recall", tp / (tp + fn))],["metric", "value"])
metrics.show()
evaluator = BinaryClassificationEvaluator(
labelCol="trueLabel",
rawPredictionCol="prediction",
metricName="areaUnderROC")
aur = evaluator.evaluate(prediction)
print(aur)
val prediction = model.transform(test)
val tp = prediction.filter("prediction == 1 AND truelabel == 1").count().toFloat
val fp = prediction.filter("prediction == 1 AND truelabel == 0").count().toFloat
val tn = prediction.filter("prediction == 0 AND truelabel == 0").count().toFloat
val fn = prediction.filter("prediction == 0 AND truelabel == 1").count().toFloat
val metrics = spark.createDataFrame(Seq(
("TP", tp),
("FP", fp),
("TN", tn),
("FN", fn),
("Precision", tp / (tp + fp)),
("Recall", tp / (tp + fn)))).toDF("metric", "value")
metrics.show()
val evaluator = new BinaryClassificationEvaluator().
setLabelCol("trueLabel").
setRawPredictionCol("prediction").
setMetricName("areaUnderROC")
val aur = evaluator.evaluate(prediction)
println("AUR = " + (aur))
CrossValidator()
By Fabian Flöck - Own work, CC BY-SA 3.0, https://commons.wikimedia.org/w/index.php?curid=51562781

| parameter | description |
|---|---|
| estimator | pipeline or model to estimate parameters |
| evaluator | evaluator to get best parameters |
| estimatorParamMaps | grid of parameters |
| numFolds | Number of iterations (how split data) |
from pyspark.ml.tuning import ParamGridBuilder, CrossValidator
paramGrid = ParamGridBuilder().\
addGrid(lr.regParam, [0.3, 0.01]).\
addGrid(lr.maxIter, [10, 5]).\
build()
cv = CrossValidator(estimator=pipeline,
evaluator=RegressionEvaluator(),
estimatorParamMaps=paramGrid,
numFolds=2)
model = cv.fit(train)
import org.apache.spark.ml.tuning.{ParamGridBuilder, CrossValidator}
val paramGrid = new ParamGridBuilder().
addGrid(lr.regParam, Array(0.3, 0.01)).
addGrid(lr.maxIter, Array(10, 5)).
build()
val cv = new CrossValidator().
setEstimator(pipeline).
setEvaluator(new RegressionEvaluator).
setEstimatorParamMaps(paramGrid).setNumFolds(2)
val model = cv.fit(train)

0.790642173833
Text Analyze
Preprocessing / Prepare Data
Tokenizer()
Split the text into individual words

from pyspark.ml.feature import Tokenizer
tokenizer = Tokenizer(
inputCol="SentimentText",
outputCol="SentimentWords")
tokenized = tokenizer.transform(train)
tokenized.select("SentimentText","SentimentWords").show(5, truncate = False)
import org.apache.spark.ml.feature.Tokenizer
val tokenizer = new Tokenizer().
setInputCol("SentimentText").
setOutputCol("SentimentWords")
val tokenized = tokenizer.transform(train)
tokenized.select("SentimentText",
"SentimentWords").show(5,truncate = false)
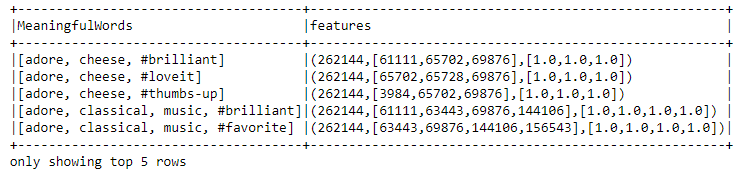
StopWordsRemover()
Removed stop words that are not important in the sentence (like ‘a’,‘the’, etc…)

from pyspark.ml.feature import StopWordsRemover
swr = StopWordsRemover(
inputCol=tokenizer.getOutputCol(),
outputCol="MeaningfulWords")
swr_output = swr.transform(tokenized)
swr_output.select(tokenizer.getOutputCol(),
"MeaningfulWords").show(5, truncate = False)
import org.apache.spark.ml.feature.StopWordsRemover
val swr = new StopWordsRemover().
setInputCol(tokenizer.getOutputCol).
setOutputCol("MeaningfulWords")
val swr_output = swr.transform(tokenized)
swr_output.select(tokenizer.getOutputCol,
"MeaningfulWords").show(5, truncate = false)
HashingTF()
Generate numeric vectors from the text values
from pyspark.ml.feature import HashingTF
hashTF = HashingTF(
inputCol=swr.getOutputCol(),
outputCol="features")
hashTF_output = hashTF.transform(swr_output)
hashTF_output.select(
swr.getOutputCol(),
"features").show(5, truncate = False)
import org.apache.spark.ml.feature.HashingTF
val hashTF = new HashingTF().
setInputCol(swr.getOutputCol).
setOutputCol("features")
val hashTF_output = hashTF.transform(swr_output)
hashTF_output.select(
swr.getOutputCol,
"features").show(5, truncate = false)
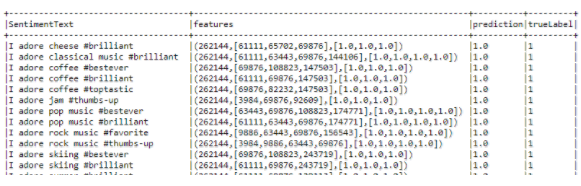
Using in Machine Learning
Based on the label (if it’s positive text or negative review) we can define predict the value.
lr = LogisticRegression(
labelCol="label",
featuresCol="features", maxIter=10, regParam=0.01)
pipeline = Pipeline(stages=[tokenizer, swr, hashTF, lr])
piplineModel = pipeline.fit(train)
prediction = piplineModel.transform(test)
prediction.select("SentimentText",
"features",
"prediction",
"trueLabel").show(10,truncate = False)
val lr = new LogisticRegression().
setLabelCol("label").
setFeaturesCol("features").
setMaxIter(10).
setRegParam(0.01)
val pipeline = new Pipeline().
setStages(Array(tokenizer, swr, hashTF, lr))
val piplineModel = pipeline.fit(train)
val prediction = piplineModel.transform(test)
prediction.select("SentimentText",
"features",
"prediction",
"trueLabel").show(10,truncate = false)
Recommendation / Collaborative filtering
Recommendation is system to recommend some features based on the information what user like and what other users like (like shopping, movies, etc.)
https://en.wikipedia.org/wiki/Collaborative_filtering
ALS
https://spark.apache.org/docs/latest/mllib-collaborative-filtering.html#collaborative-filtering
Preprocessing / Prepare Data
| parameter | description |
|---|---|
| maxIter | Maximum number of iterations |
| regParam | Regularization parameter |
| userCol | column name for user ids |
| itemCol | column name for items id |
| ratingCol | column name for ratings |
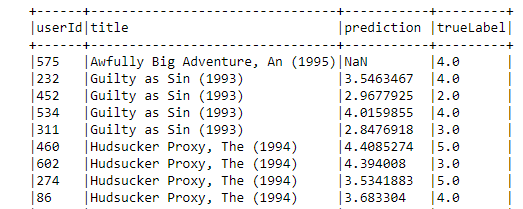
from pyspark.ml.recommendation import ALS
als = ALS(
maxIter=5,
regParam=0.01,
userCol="userId",
itemCol="movieId",
ratingCol="label")
model = als.fit(train)
prediction = model.transform(test)
prediction.join(movies, "movieId").\
select("userId", "title", "prediction", "trueLabel").\
show(100, truncate=False)
import org.apache.spark.ml.recommendation.ALS
val als = new ALS().
setMaxIter(5).
setRegParam(0.01).
setUserCol("userId").
setItemCol("movieId").
setRatingCol("label")
val model = als.fit(train)
val prediction = model.transform(test)
prediction.join(movies, "movieId").
select("userId", "title", "prediction", "trueLabel").
show(100, truncate=false)
Clustering
Preprocessing / Prepare Data
K-means clustering
https://en.wikipedia.org/wiki/K-means_clustering
By Chire [GFDL (http://www.gnu.org/copyleft/fdl.html) or CC BY-SA 4.0 (https://creativecommons.org/licenses/by-sa/4.0)], from Wikimedia Commons
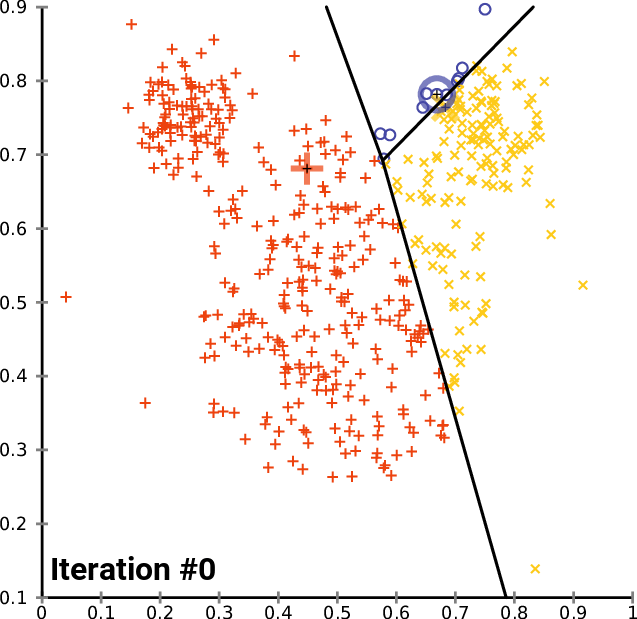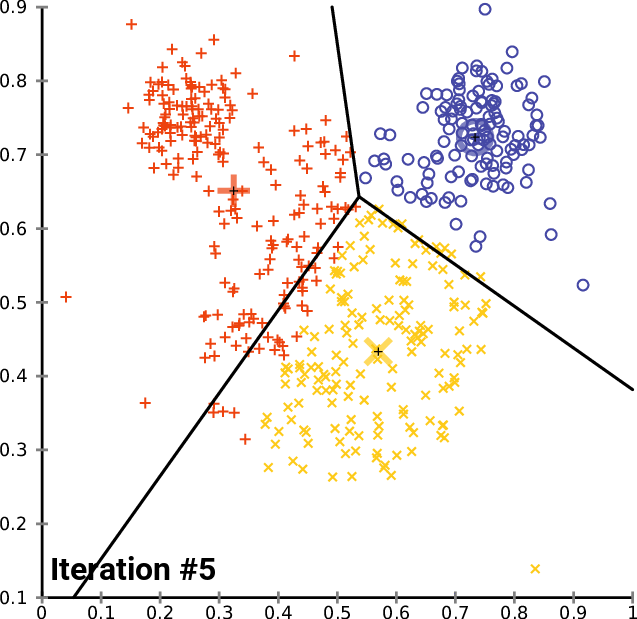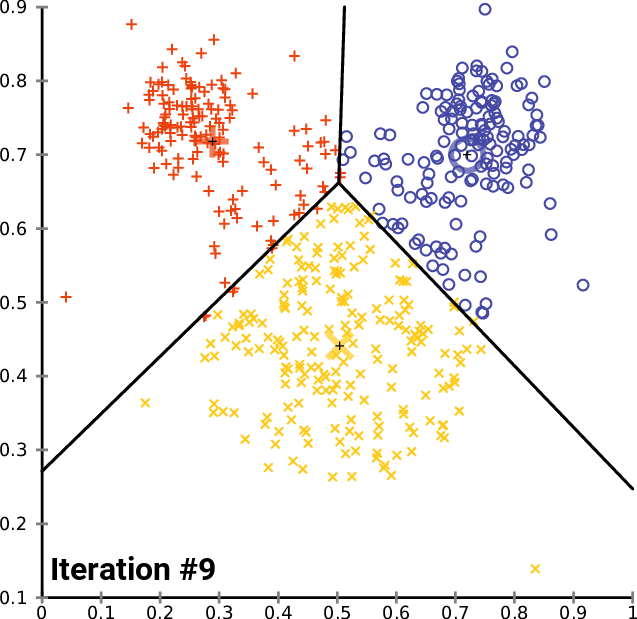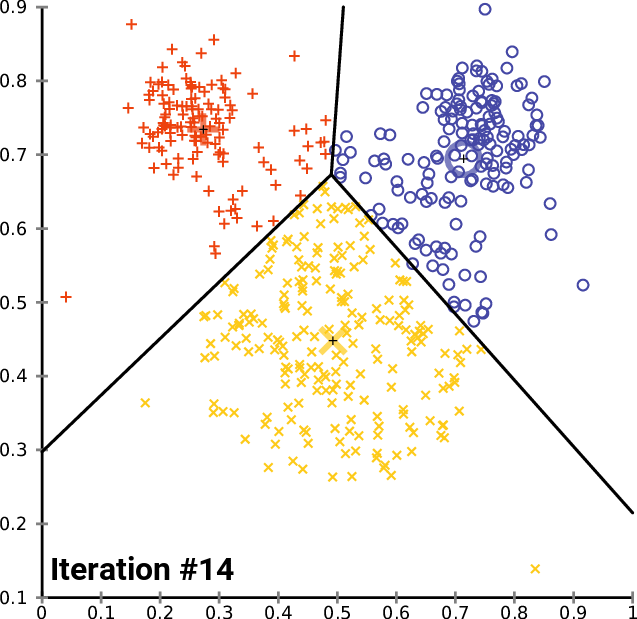
Train
from pyspark.ml.clustering import KMeans
kmeans = KMeans(
featuresCol=assembler.getOutputCol(),
predictionCol="cluster",
k=5,
seed=0)
model = kmeans.fit(train)
import org.apache.spark.ml.clustering.KMeans
val kmeans = new KMeans().
setFeaturesCol(assembler.getOutputCol).
setPredictionCol("cluster").
setK(5).
setSeed(0)
val model = kmeans.fit(train)
Get centers()
# 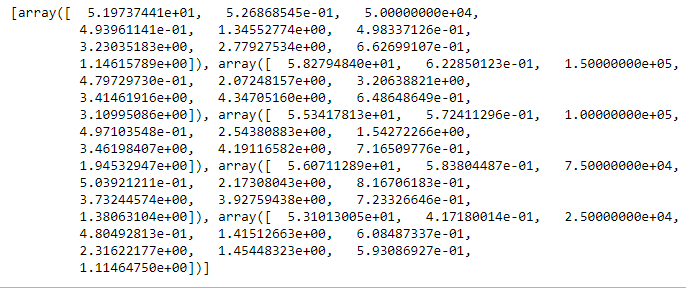
model.clusterCenters()
model.clusterCenters
Predict


prediction = model.transform(train)
prediction.groupBy("cluster").\
count().\
orderBy("cluster").\
show()
prediction.select("CustomerName",
"cluster").show(50)
val prediction = model.transform(train)
prediction.groupBy("cluster").
count().
orderBy("cluster").
show()
prediction.select("CustomerName",
"cluster").show(50)