Links
http://pandas.pydata.org/Pandas_Cheat_Sheet.pdf
Data Types
Source: https://developer.rhino3d.com/guides/rhinopython/python-datatypes/
| Data Type | Example | Description |
|---|---|---|
bool ↶ boolhtml source | True, False | Boolean |
int ↶ inthtml source | 10 | Signed integer (in Python3 the same as long) |
long ! ↶ longhtml source Only for Python less than 3.0. In python >= 3.0 use int data type. | 345L | Long (Python less than 3 only) |
float ↶ floathtml source | 34.5 | (.) Floating point real values |
complex ↶ complexhtml source | 3.14J | Complex data type a+bi where $$i^2=-1$$ |
decimal ↶ decimalhtml source | Decimal(3.12) | from decimal import Decimal - required |
fraction ↶ fractionhtml source | Fraction(3,4) | from fractions import Fraction -required ¾ - fraction |
tuple ↶ tuplehtml source | (1,2,3) | Tuple |
list ↶ listhtml source | [1,2,3] | List |
dictionary ↶ dictionaryhtml source | {'john': 425, 'tom': 212} | Dictionary |
bytearray ↶ bytearrayhtml source | bytearray('Text','utf-8') | Bytearray |
List Operations
| Command | Output |
|---|---|
[1,2,3] | [1,2,3] |
l = [1,'2',3] | [1,'2',3] |
l *2 | [1,2,3,1,2,3] |
l[0] | 1 (int) |
len(l) | 3 (int) |
l = [1,0,4,2] | |
l.sort() ! This function returns nothing, operate on the list itself. | l = [0,1,4,2] |
l = [1,0,-2,"-4","1","5"]l.sort(key=int) | l = [‘-4’,-2,0,‘1’,‘5’] key is convertion method |
l.reverse()! This function returns nothing, operate on the list itself. | l = ['5', '1', 1, 0, -2, '-4'] |
l+[1,2] | ['5', '1', 1, 0, -2, '-4', 1, 2] |
[x**2 for x in range(6)] | [0,1,4,9,16,25] |
l.append(3)! This function returns nothing, operate on the list itself. | l =['5', '1', 1, 0, -2, '-4', 3] |
l.remove('1') | l = ['5', 1, 0, -2, '-4', 3] |
Slices
| Example | Output | Description |
|---|---|---|
R = range(2,20,3) | range(2,20,3) | Returns a range for loop function, from 2 to 10 by 3 |
L = list(range(2,20,3)) | [2, 5, 8, 11, 14, 17] | List from range, from 2 to 10 by 3 |
R[:1] | range(2, 5, 3) #[2] | splice from range |
L[:1] | [2] | splice from list |
V = list(range(0,5)) | [0, 1, 2, 3, 4] | Vector |
V[0] | 0 | first element index |
V[-1] | 4 | last element index |
V[-3] | 2 | |
V[-3:-1] | [2,3] | from last three to last one (without last one) |
'abc'[-3:-1] | ‘ab’ | |
V[0:3:2] | [0,2] | from first to 3rd by 2 |
'abc'[0:3:2] | ac | |
V[::2] | [0,2,4] | all by 2 |
'abc'[::2] | ‘ac’ | |
V[::-1] | [4, 3, 2, 1, 0] | reverse |
'abc'[::-1] | ‘cba’ | reverse text |
OS
import os
import glob
| Example | Output | Description |
|---|---|---|
os.getcwd() | C:\\public\\PROJECTS\examples\ | Get current Directory |
os.listdir('.') | ["file1.py","image.png"] | Get list of files |
os.listdir('c:\\') | ['$Recycle.Bin','Windows',...]… | Get list of files from the directory |
glob.glob('./*.png') | ["image.png"] | Get all images |
for dir in os.walk('.') | ‘.’,'.git',... | Iteration to walk through all directories |
[d[0] for d in os.walk('.')] | ['.','.git',...] | list of all subfolders |
Random
import random as r
| Example | Output | Description |
|---|---|---|
random.choise([1,2,3]) | 2 | Select random one values |
random.sample([1,2,3],2) | [1,3] | Select random 2 values |
Data.Frame
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
Create ? ↶ pd.DataFrame
html source
pd.DataFrame
From Dictionary:
df = pd.DataFrame(
{"a" : [4 ,5, 6],
"b" : [7, 8, 9],
"c" : [10, 11, 12]},
index = [1, 2, 3])

From List
lst = [[1,2,3],[4,5,6]]
df = pd.DataFrame(lst,columns = ['A','B','C'])

import data
| Name | Description | Example |
|---|---|---|
pd.read_csv ↶ pd.read_csvhtml source | Read csv file | pd.read_csv('name.csv',header=0,index_col=0) |
Select
More examples: https://www.shanelynn.ie/select-pandas-dataframe-rows-and-columns-using-iloc-loc-and-ix/
dic = {"a" : [4 ,5, 6, 7],"b" : [8, 9, 10, 11],"c" : [12, 13, 14, 15]}
df = pd.DataFrame(dic,index = [0, 1, 2, 3])

| Example | Output | Description |
|---|---|---|
df[:2] | # | Select first two rows (0 and 1, :2 means without 2) |
df[-1:] | # | Last row |
df[1:2] | # | Select row from 1 to 2 (without 2) |
df["b"] | # | Column b (output is pandas.Series) |
df.b | # | Select column b (output is pandas.Series) |
df[["b","c"]] | # | Columns ‘b’and ‘c’ |
df.loc[1:2,["b","c"]] | # Different behaviour than df[1:2], in previous it selects without :2, in .loc it selects with :2 | row 1 and 2, columns ‘b’and ‘c’(with 2) |
df.loc[:,'a':'c'] | # | all rows, columns from ‘a’to ‘c’ |
df.iloc[:,0:2] | # | all rows, columns from 0 to 2 (without 2) |
df['a']>5 | # | Return if column ‘a’is greater than 5 |
(df['a']>5) & (df['b']>10) | # | combine two conditions |
df[df['a']>5] | # | Filter by condition |
df.shape[0] | 4 | Number of rows |
df[df['a']>5].shape[0] | 2 | Number of rows after filter |
df.shape[1] | 3 | Number of columns |












Row Operations
| Example | Output | Description |
|---|---|---|
df.loc[4] = [-1,-2,-3] | # | Add/Replace row |
df = df.append([{ 'a': 1,'b':2,'c':3}] , ignore_index = True) | # | Add rows ? ↶ Performance is slower than on the listhtml source |
df = df.append([{ 'a': 1,'b':2,'c':3}] ) | # | Add rows |
df = df.append(df) | # | Add DataFrame |
df = df.append(df,ignore_index=True) | # | Add DataFrame |
df = pd.concat([df,df]) | # | Concat DataFrames |






Column Operations
| Example | Output | Description |
|---|---|---|
df['d']=np.nan | # | Fill column with NaN values |
df['d'] = df['a']+df['b'] | # | Fill column with adding two olumns |
df.insert(0,'a0',3) | # | Insert column at the begining (0 position) |
df = df.assign(d=5) | # | Add new column |
df = df.assign(d = lambda x: x.a+x.b) | # | Add new column from function |





Numpy
array_1d = np.array([1, 2, 3]) #1 dimensional array
array_2d = np.array([[1,2,3],[4,5,6]]) #2 dimensional array


| Example | Output | Description |
|---|---|---|
np.array([1, 2, 3]) | # | Create numpy array |
np.array([[1,2,3],[4,5,6]]) | # | Create a two dimensional array |
array_1d.shape | (3,) | Shape of the 1d array |
array_2d.shape | (2, 3) | Shape of the 2d array |
np.arange(12) | # | array with elements from 0 to 11. |
np.max(df[["b","c"]]) | # | max from columns “b”and “C” |
np.max(df["a"]) | # | max from column “a” |
np.mean(array_1d) | 2.0 | mean |
np.mean(array_2d) | 3.5 | mean from 2D array (for all elements) |
np.median(array_1d) | 2.0 | median |
np.std(array_1d) | 0.816496580927726 | standard deviation |
np.var(array_1d) | 0.6666666666666666 | variance |
np.sum(array_1d) | 6 | sum |
np.cumsum(array_1d) | array([1, 3, 6], dtype=int32) | running sum |
np.sort([6,3,5]) | array([3, 5, 6]) | sorted values |
np.sort([[7,5,6],[4,1,3]]) | # | sorted 2d values |
np.random.normal(1100,222,3) | # | random with normal distribution, loc= 1100 (center) scale= 222 (spread) size= 3 (elements) |
array_1d[None] | array([[1, 2, 3]]) (shape: (1,3)) | Create second dimension of array (array of array) |






Sort
import pandas as pd
df = pd.DataFrame({"A":["a","b","c","a"], "B": [2,5,0,1]})
| Example | Output | Description |
|---|---|---|
df.sort_values(“A”) | # | Sort values by the column A |
df.sort_values(["A","B"]) | # | Sort values by columns A and B |
df.sort_values(["A","B"],ascending=[False,True]) | # | Sort values by the column A descending and the column B ascending |



Group calculations
import numpy as np
import pandas as pd
dic = {"a" : ['a' , 'a', 'a', 'b', 'c'], "b" : [1, 2, 2, 3, 2], "c" : [1,1, 1, 1, 15]}
df = pd.DataFrame(dic,index = [0, 1, 2, 3, 4])
df2 = df.groupby(['a']).agg(['sum','mean']).reset_index()


| Example | Output | Description |
|---|---|---|
df.sum() | # | Sum of rows. Other: max,min,count,mean |
df.cumsum() | # | Running sum. Other:cummax,cummin |
df.sum(axis=1) | # | Sum of columns |
df.groupby(['a']).sum() | # | Sum by group |
df.groupby(['a']).agg(['sum','mean']) | # | Sum and Mean of column |
df.groupby(['a']).agg( { 'b': ['max','min','sum'], 'c': ['sum'] }) | # | Aggregation for each column |
df.groupby(['a']).agg( { 'c': lambda x: np.max(x) }) | # | Own function |
df.groupby(['a']).agg( { 'b': { 'max': 'max', 'count_max': lambda x: x[x==np.max(x)].count()} }) | # | Count maximum values of column b |








Column/Index operations
| Example | Output | Description |
|---|---|---|
df2.b | # | All b columns |
df2.b['sum'] | # | From column (‘b’, ‘sum’) |
df2.loc[3,('b','sum')] | 11 | 3rd row from column (‘b’,‘sum’) |
df2.loc[3,[('b','sum'),('a','')]] | # | 3rd row, column(‘b’,‘sum’) and ‘a’ |
df2.iloc[3,1] | 11 | 3rd from from column 1 (‘b’,‘sum’) |
df = df.groupby(['a']).sum().reset_index() | # | Move index from ‘a’to column and create new index. |
df2.columns = df2.columns.map('_'.join).str.strip() | # | Remove hierachy columns from DataFrame |





Categories
import pandas as pd
df = pd.DataFrame({"A":["a","b","c","a"]})
| Example | Output | Description |
|---|---|---|
df["B"] = df["A"].astype("category") | # | Convert to category |
df['B'].cat.reorder_categories(['b','c','a'], ordered=True ) | # | Reorder categories |
df['B'] = df['B'].cat.rename_categories(['BB','CC','AA']) | # | Rename categories |



Ipython/Jupyter
Run jupyter
jupyter notebook
Setup password instead of token
If you don’t want to use url for jupyter with the token you can replace it with the password for the jupyter notebook.
Instead of
http://localhost:8888/?token=c8de56fa4deed24899803e93c227592aef6538f93025fe01
You go to the jupyter webpage by the link:
http://localhost:8888
jupyter notebook password

Run Jupyter on ssh more
- Setup password for jupyter notebook (not required)
jupyter notebook password
- Run jupyter notebook.
--ipis the port number,--ip=0.0.0.0- allows you to go to a webpage from any source ip.
jupyter notebook --no-browser --port=8002 --ip=0.0.0.0
- On local machine run ssh tunnellink
ssh -N -f -L localhost:8002:localhost:8002 user@ip_adress
If you got certificate (like AWS), for the ssh you need to add your private key (.pem file) in the command
ssh -i key.pem user@ip_address
ssh -i key.pem user@ip_address -N -f -L localhost:8002:localhost:8002 user@ip_adress
Next on the local machine run ssh tunneling:
localhost:8002is local port,localhost:8000port run on the ipython notebook , Can be the same as aboveuser- user name,ip_adress- ip address for the ssh).
- go to the webpage with the selected port (add the token link if you don’t set up a password):
Hide warnings
import sys
import warnings
if not sys.warnoptions:
warnings.simplefilter("ignore")
Show all columns
from IPython.display import display
pd.options.display.max_columns = None
Larger plot
import matplotlib.pyplot as plt
plt.rcParams['figure.figsize'] = [10, 5]
Reload module
Python 2
import numpy as np # linear algebra
reload(np)
Python 3
from imp import reload
import numpy as np # linear algebra
reload(np)
Python >=3.4
from importlib import reload
import numpy as np # linear algebra
reload(np)
Autoreload module in Jupyter/Ipython
Reload all modules (except those excluded by %aimport) every time before executing the Python code typed.
%load_ext autoreload
%autoreload 2
Reload all modules imported with %aimport every time before executing the Python code typed.
%autoreload 1
Disable automatic reloading.
%autoreload 0
Reload all modules (except those excluded by %aimport) automatically now.
%autoreload
Keyboard shortcuts
Source: https://www.cheatography.com/weidadeyue/cheat-sheets/jupyter-notebook/
Both modes:
| Key | Description |
|---|---|
Shift+Enter | run cell, select bellow |
Ctrl+Enter | run cell, keep at cell |
Alt+Enter | run cell, insert bellow |
Command Mode (Esc to enable)
| Key | Description |
|---|---|
↑ or k | Go Up |
↓ or j | Go Down |
a | Add cell above |
b | Add cell below |
d,d | delete cell |
x | cut cell |
c | copy cell |
v | paste cell |
z | undo last cell deletion |
0,0 | restart kernel |
y | convert to code |
m | convert to markdown |
r | convert to raw |
shift+m | merge with the next cell |
Edit Mode (Esc to enable):
| Key | Description |
|---|---|
Esc | Move to Command mode |
ctrl+] | indent selected cells |
ctrl+[ | dedent selected cells |
ctrl+a | select all |
ctrl+z | undo |
ctrl+shift+z or ctrl+y | redo |
ctrl+backspace | delete word before |
ctrl+delete | delete word after |
ctrl+shift+- | split cell on the cursor into two cells |
ctrl+s | save |
ctrl+/ | toggle comments |
Magic and cell commands
More: https://www.dataquest.io/blog/jupyter-notebook-tips-tricks-shortcuts/
| Command | Info | Description |
|---|---|---|
%magic | # | Info about magic function |
%%lsmagic | # | List all magic commands |
%time | # | Time for a single command |
%%time | # | Time for run single cell |
%timeit | # | TimeIt for single commnad |
%%timeit | # | Mean and Standard Devaition of running cell couple times. |
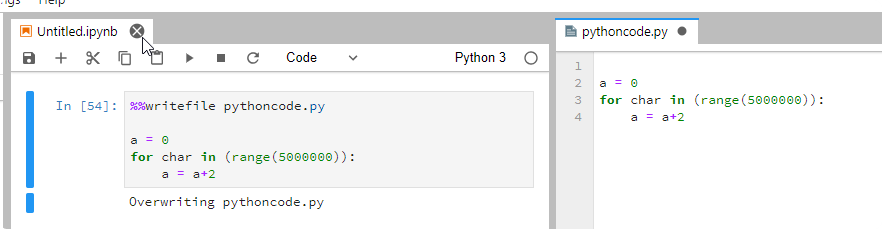
%%writefile pythoncode.py | # | Write python code to the file |
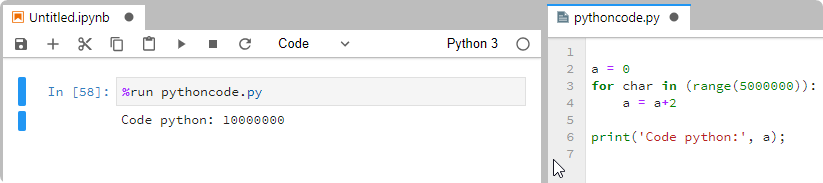
%run pythoncode.py | # | Run python code |
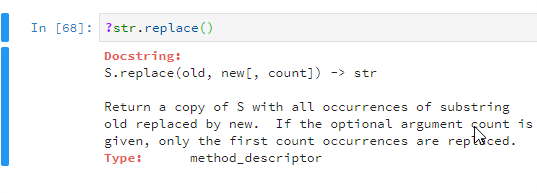
?str.replace() | # | Describes command |
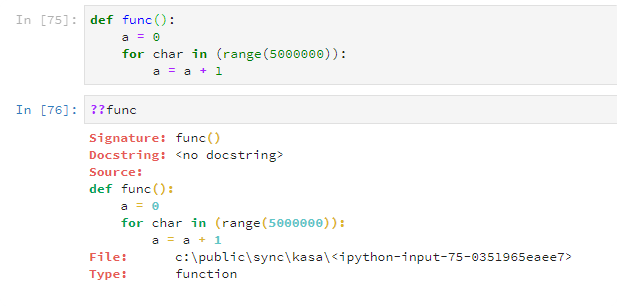
??func | # | Display the source of the command |
!command | Run shell command (for example ls) | |
!ls *.csv | # | list all *.csv files |
!pip install numpy | # | install by pip |
%%html | # | Treat cell as a HTML |








Jupyter/Show Progress (tdqm)
source: https://github.com/tqdm/tqdm#installation

from tqdm import tqdm
a = 0
for i in tqdm(range(10000000)):
a = a+1